
목차
- 인덱스(INDEX)
1-1. INDEX와 ROWID
1-2. 인덱스 장단점
1-3. 데이터 딕셔너리 - 인덱스 힌트
- 인덱스 종류
3-1. 고유 인덱스(UNIQUE INDEX)
3-2. 비고유 인덱스(NONUNIQUE INDEX)
3-3. 단일 인덱스(SINGLE INDEX)
3-4. 결합 인덱스(COMPOSITE INDEX)
3-5. 함수 기반 인덱스(FUNCTION BASED INDEX)
학습점검
✅ INDEX 객체의 사용 목적에 대해 이해할 수 있다.
✅ INDEX 객체에 대해 이해할 수 있다.
✅ INDEX 객체의 장점과 단점에 대해 이해할 수 있다.
✅ 자동 생성되는 INDEX 객체를 사용할 수 있다.
✅ CREATE INDEX 구문을 이용하여 INDEX 객체를 생성할 수 있다.
✅ INDEX의 구조에 대해 이해할 수 있다.
✅ INDEX를 이용한 실행 계획의 유형을 이해할 수 있다.
✅ INDEX의 종류에 대해 이해할 수 있다.
✅ INDEX를 활용하여 보다 성능이 향상된 쿼리문을 작성할 수 있다.
1. 인덱스(INDEX)
- 인덱스(INDEX)란, SQL 명령문의 검색 처리 속도 향상을 목적으로 컬럼에 대해 생성하는 오라클 객체(OBJECT)이다.
1-1. INDEX와 ROWID
- 인덱스는 하드디스크의 어느 위치에 있는지에 대한 정보를 가진 주소록이다.
- 인덱스 내부 구조는 이진트리(B* 트리) 형식으로 DATA-ROWID가 구성돼 있다.
- 예시에서는 인덱스 EMP_ID와 물리적 위치인 ROWID가 함께 배정돼 있는 것이다. 이를 활용하면 풀스캔 하는 대신에 정확한 ROWID를 찾아가도록 만들어 작업 속도 단축까지 유도할 수 있다.
- 여기서 ROWID는 오브젝트 번호, 상대파일 번호, 블록 번호, 데이터 번호를 갖추고 있다.
-- ROWID 조회
SELECT
ROWID
, E.EMP_ID
, E.EMP_NAME
FROM EMPLOYEE E;
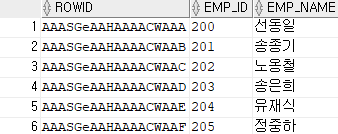
- 조회 결과 EMP_ID따라 ROWID 또한 순차적으로 끝글자 A~F로 번호가 부여되었음을 알 수 있다.
1-2. 인덱스 장단점
인덱스 활용이 마냥 좋은 결과만 낳지는 않는다. 아래 장단점을 비교해보자.
- 장점 ①. 검색 속도가 빨라진다.
- 장점 ②. 시스템에 걸리는 부하를 줄여 시스템 전체의 성능을 향상시킨다.
- 단점 ①. 인덱스 위한 추가 저장 공간을 필요로 한다.
- 단점 ②. 인덱스 생성하는 데 시간이 소요된다.
-- INDEX REBUILD
✅ ALTER INDEX 인덱스명 REBUILD;
- 단점 ③. 데이터 변경 작업(DML 작업, INSERT-UPDATE-DELETE)이 빈번한 경우 처리 속도가 느려진다. 데이터 변경 과정에서 정렬해놓은 값들이 바뀌고 섞이게 마련이라 이에 대한 리빌드(REBUILD)가 요구된다. 따라서 REBUILD 작업을 주기적으로 행해야 하는데, REBUILD를 자주 하지 못하면 인덱스 트리 구조가 불균형하게 돼 오히려 성능 저하로 이어지는 것이다.
- 특히 DELETE와 같은 DML 작업 명령을 수행한 경우, 해당 인덱스 엔트리가 논리적으로만 제거되고 실제 엔트리는 그냥 남아있게 된다. 제거된 인덱스가 공간을 차지하고 있는 것이기에 이러한 인덱스를 재생성(REBUILD)할 필요가 있다.
1-3. 데이터 딕셔너리
✅ SELECT UIC.*
FROM USER_IND_COLUMNS UIC;
- PRIMARY KEY(PK) 또는 UNIQUE 제약 조건의 경우 생성과 동시에 INDEX가 자동 부여된 모습을 확인할 수 있다.
- 고유 식별자 역할을 하는 PK이고, 값의 중복이 없는 UNIQUE이기에 데이터를 특정할 수 있다는 특성상 자동으로 INDEX 오브젝트까지 만들어지는 것이다. 이들은 아래서 서술할 고유 인덱스(UNIQUE INDEX)이다.
2. 인덱스 힌트
- 일반적으로 옵티마이저(Optimizer, SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진)가 인덱스는 타거나 풀 스캐닝을 거치는 방법 중 비용이 적게 드는 효율적인 방식으로 검색하도록 만든다. 비용이라 함은 얼마나 많이 검색하고 어느 정도 시간이 소요되는가를 말한다.
- 옵티마이저가 처리하도록 두는 것이 아니라, 원하는 테이블에 있는 인덱스를 사용하도록 구문(힌트)를 작성해 선택할 수도 있다.
✅ SELECT /*+ INDEX(테이블명 인덱스명)*/
SELECT /*+ INDEX(E 엔티티1_PK)*/ -- 테이블 별칭도 사용 가능
E.*
FROM EMPLOYEE E;
- SELECT 첫 줄에 위와 같은 힌트 주석을 작성해 적절한 인덱스를 부여하는 방법이다.
- 플러스(+) 연산자 뒤로 반드시 띄어쓰기 해야 한다.
SELECT /*+ INDEX_DESC(E 엔티티1_PK)*/
E.*
FROM EMPLOYEE E;
- 인덱스를 내림차순 정렬할 수 있다. 인덱스 영역으로부터 역방향으로 스캔하라는 뜻이다.
- 오래된 순으로 예전에 등록한 데이터가 먼저 읽히도록 정렬한다.

- 상단의 계획 설명 아이콘(단축키 F10)을 눌러 어떤 INDEX가 사용됐는지 살필 수 있다.

- 계획 설명란에 OBJECT_NAME, OPTIONS, CARDINALITY, COST 컬럼이 출력되는 모습이다.
3. 인덱스 종류
일반적으로 고유 값에 대해 자동 생성된다. 고유 인덱스 외에는 필요에 따라 쓰인다.
3-1. 고유 인덱스(UNIQUE INDEX) PK, UNIQUE
-- UNIQUE INDEX 생성 시도 중복 값이 들어있어 X
CREATE UNIQUE INDEX IDX_DEPTCODEON EMPLOYEE(DEPT_CODE);중복 불가
▶중복 키가 있습니다. 유일한 인덱스를 작성할 수 없습니다
- UNIQUE INDEX로 생성된 컬럼에는 중복 값이 포함될 수 없다.
-- UNIQUE INDEX 생성 시도 PK 또는 UNIQUE 제약조건 따라 이미 존재하므로 X
CREATE UNIQUE INDEX IDX_EMPNOON EMPLOYEE(EMP_NO);생성 불가
▶열 목록에는 이미 인덱스가 작성되어 있습니다
- 예시에서는 UNIQUE 제약 조건에 의해 이미 INDEX가 생성돼 있어 오류가 나타난다.
- 오라클의 PRIMARY KEY(PK), UNIQUE 제약조건을 생성하면 자동으로 해당 컬럼에 대해 UNIQUE INDEX가 생성된다. 관련 컬럼으로 접근(ACCESS)하는 경우 성능 향상의 효과가 있다.
-- UNIQUE INDEX 삭제 시도 PK 또는 UNIQUE 제약조건 걸려있어 XDROP INDEXSYS_C008775;삭제 불가
▶고유/기본 키 적용을 위한 인덱스를 삭제할 수 없습니다.
- EMPLOYEE 테이블의 EMP_NO 컬럼에 해당하는 INDEX 삭제 시도한 경우이다.
- PRIMARY KEY(PK) 또는 UNIQUE 제약 조건 따라 생성된 INDEX는 DROP 할 수 없다.
3-2. 비고유 인덱스(NONUNIQUE INDEX)
CREATE INDEX IDX_DEPTCODE -- UNIQUE 키워드만 빠진 형태
ON EMPLOYEE(DEPT_CODE);
- WHERE절에서 빈번하게 사용되는 일반 컬럼 대상으로 생성한다.
- 즉 고유 값은 아니지만 조회에 많이 쓰이는 값이기에 인덱스를 타는 것이 효율적일 때 사용된다.
- 주로 성능 향상 목적으로 생성되는 인덱스이다.
3-3. 단일 인덱스(SINGLE INDEX)
- 한 개의 컬럼으로 구성한 인덱스이다.
3-4. 결합 인덱스(COMPOSITE INDEX)
- 여러 개의 컬럼을 묶어서 표현하는 인덱스이다.
- 결합 인덱스를 쓸 때 중복 정도가 낮은 값을 먼저 서술하는 것이 검색 속도를 향상시킨다.
CREATE INDEX IDX_DEPT
ON DEPARTMENT(DEPT_ID, DEPT_TITLE);
- 예시에서도 보다 UNIQUE한 값인 DEPT_ID를 앞에 작성해 성능 향상을 꾀한다.
-- INDEX HINT 작성
SELECT /*+ INDEX_DESC(D IDX_DEPT)*/
D.DEPT_ID
FROM DEPARTMENT D
WHERE D.DEPT_TITLE > '0'
AND D.DEPT_ID > '0';

- WHERE 조건절이 문자 '0'보다 크다는 것은 결국 데이터 모두 TRUE로 만드는 의미이다. WHERE절에서 해당 컬럼을 기준 삼았다고 해석하면 된다.
3-5. 함수 기반 인덱스(FUNCTION BASED INDEX)
- 보통 SELECT절이나 WHERE절에서 산술계산식 또는 함수가 사용된 경우 계산에 포함된 컬럼은 INDEX 적용을 받지 않는다.
- 계산식으로 검색하는 경우가 많다면, 수식이나 함수식으로 이루어진 컬럼을 INDEX로 만들 수 있다.
CREATE INDEX IDX_EMP_SALCALC
ON EMPLOYEE((SALARY + (SALARY * NVL(BONUS, 0))) * 12);
- 예를 들어 EMPLOYEE 테이블에서 연봉은 계산된 값이다. 이것이 정렬된 별도의 인덱스가 필요할 때는 위처럼 함수 기반 인덱스를 생성할 수 있다.
-- INDEX HINT 작성
SELECT /*+ INDEX_DESC(E IDX_EMP_SALCALC)*/ -- 연봉이 높은순으로 조회
E.EMP_ID
, E.EMP_NAME
, ((E.SALARY + (E.SALARY * NVL(E.BONUS, 0))) * 12) 연봉
FROM EMPLOYEE E
WHERE ((E.SALARY + (E.SALARY * NVL(E.BONUS, 0))) * 12) > 50000000;

- WHERE절 조건을 만족하는 대상들을 INDEX HINT에 명시한 INDEX순으로 조회한 결과이다.
'Database' 카테고리의 다른 글
| [Oracle/SQL] 14. 시스템 권한 | 객체 권한 | GRANT | REVOKE | ROLE (0) | 2022.01.28 |
|---|---|
| [Oracle/SQL] 13. 동의어 | SYNONYM | 공개 동의어 | 비공개 동의어 (0) | 2022.01.28 |
| [Oracle/SQL] 11. 시퀀스 | SEQUENCE | CURRVAL | NEXTVAL (0) | 2022.01.27 |
| [Oracle/SQL] 10. VIEW | 인라인뷰 | DDL 활용한 베이스테이블 조작 (0) | 2022.01.27 |
| [Oracle/수업 과제 practice] DDL(1~9번 문항) (0) | 2022.01.26 |